The Bring Your Own Model (BYOM) feature lets you upload your own models in the form of Python code and use them within MindsDB.
Please note that this feature is available for MindsDB Pro users. If you have a free demo account, you’ll be asked to upgrade to a dedicated AWS instance.
How It Works
You can upload your custom model via the MindsDB editor by clicking Add and Upload custom model, like this:
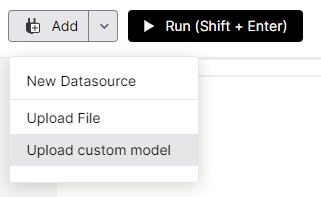
Here is the form that needs to be filled out in order to bring your model to MindsDB:
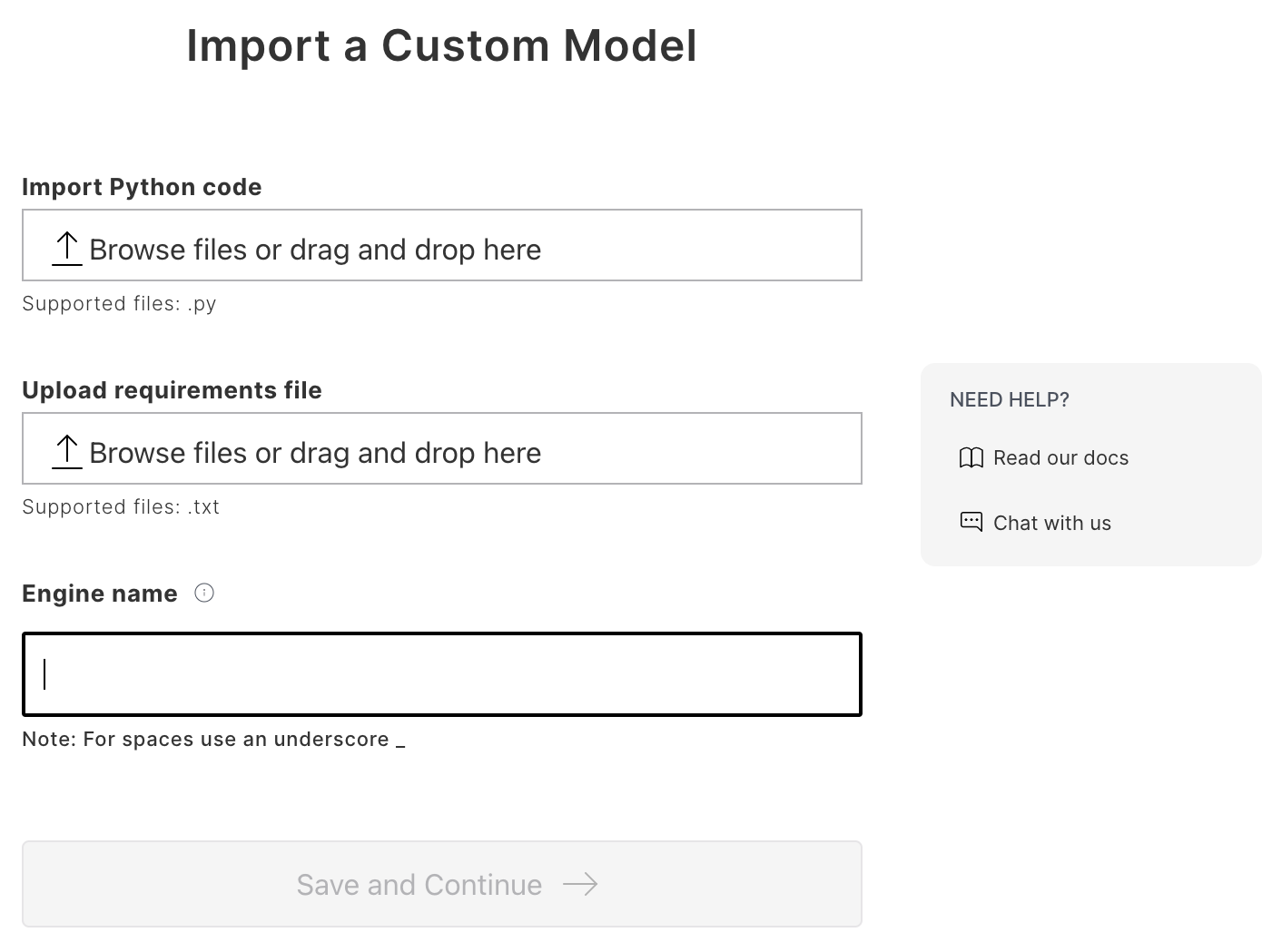
Let’s briefly go over the files that need to be uploaded:
-
The Python file stores an implementation of your model. It should contain the
train and predict methods. Here is its sample content:
import os
import pandas as pd
from sklearn.cross_decomposition import PLSRegression
from sklearn import preprocessing
class CustomPredictor():
def train(self, df, target_col, args=None):
print(args, '1111')
self.target_col = target_col
y = df[self.target_col]
x = df.drop(columns=self.target_col)
x_cols = list(x.columns)
x_scaler = preprocessing.StandardScaler().fit(x)
y_scaler = preprocessing.StandardScaler().fit(y.values.reshape(-1, 1))
xs = x_scaler.transform(x)
ys = y_scaler.transform(y.values.reshape(-1, 1))
pls = PLSRegression(n_components=1)
pls.fit(xs, ys)
T = pls.x_scores_
W = pls.x_weights_
P = pls.x_loadings_
R = pls.x_rotations_
self.x_cols = x_cols
self.x_scaler = x_scaler
self.P = P
def calc_limit(df):
res = None
for column in df.columns:
if column == self.target_col: continue
tbl = df.groupby(self.target_col).agg({column: ['mean', 'min', 'max', 'std']})
tbl.columns = tbl.columns.get_level_values(1)
tbl['name'] = column
tbl['std'] = tbl['std'].fillna(0)
tbl['lower'] = tbl['mean'] - 3 * tbl['std']
tbl['upper'] = tbl['mean'] + 3 * tbl['std']
tbl['lower'] = tbl[["lower", "min"]].max(axis=1) # lower >= min
tbl['upper'] = tbl[["upper", "max"]].min(axis=1) # upper <= max
tbl = tbl[['name', 'lower', 'mean', 'upper']]
try:
res = pd.concat([res, tbl])
except:
res = tbl
return res
trdf = pd.DataFrame()
trdf[self.target_col] = y.values
trdf['T1'] = T.squeeze()
limit = calc_limit(trdf).reset_index()
self.limit = limit
return "Trained predictor ready to be stored"
def predict(self, df):
yt = df[self.target_col].values
xt = df[self.x_cols]
xt = self.x_scaler.transform(xt)
excess_cols = list(set(df.columns) - set(self.x_cols))
pred_df = df[excess_cols].copy()
pred_df[self.target_col] = yt
pred_df['T1'] = (xt @ self.P).squeeze()
pred_df = pd.merge(pred_df, self.limit[[self.target_col, 'lower', 'upper']], how='left', on=self.target_col)
return pred_df
if __name__ == '__main__':
BYOM = CustomPredictor()
df_train = pd.read_csv('/data/work/mindsdb/test/byom/df_train.csv')
BYOM.train(df=df_train,target_col='Time')
df = BYOM.predict(df=df_train[:10])
print(df)
-
The requirements file, known as
requirements.txt, stores all dependencies along with their versions. Here is its sample content:
Once you upload the above files, please provide an engine name.
Please note that your custom model is uploaded to MindsDB as an engine. Then you can use this engine to create a model.

Let’s look at an example.
Example
We upload the custom model, as below:
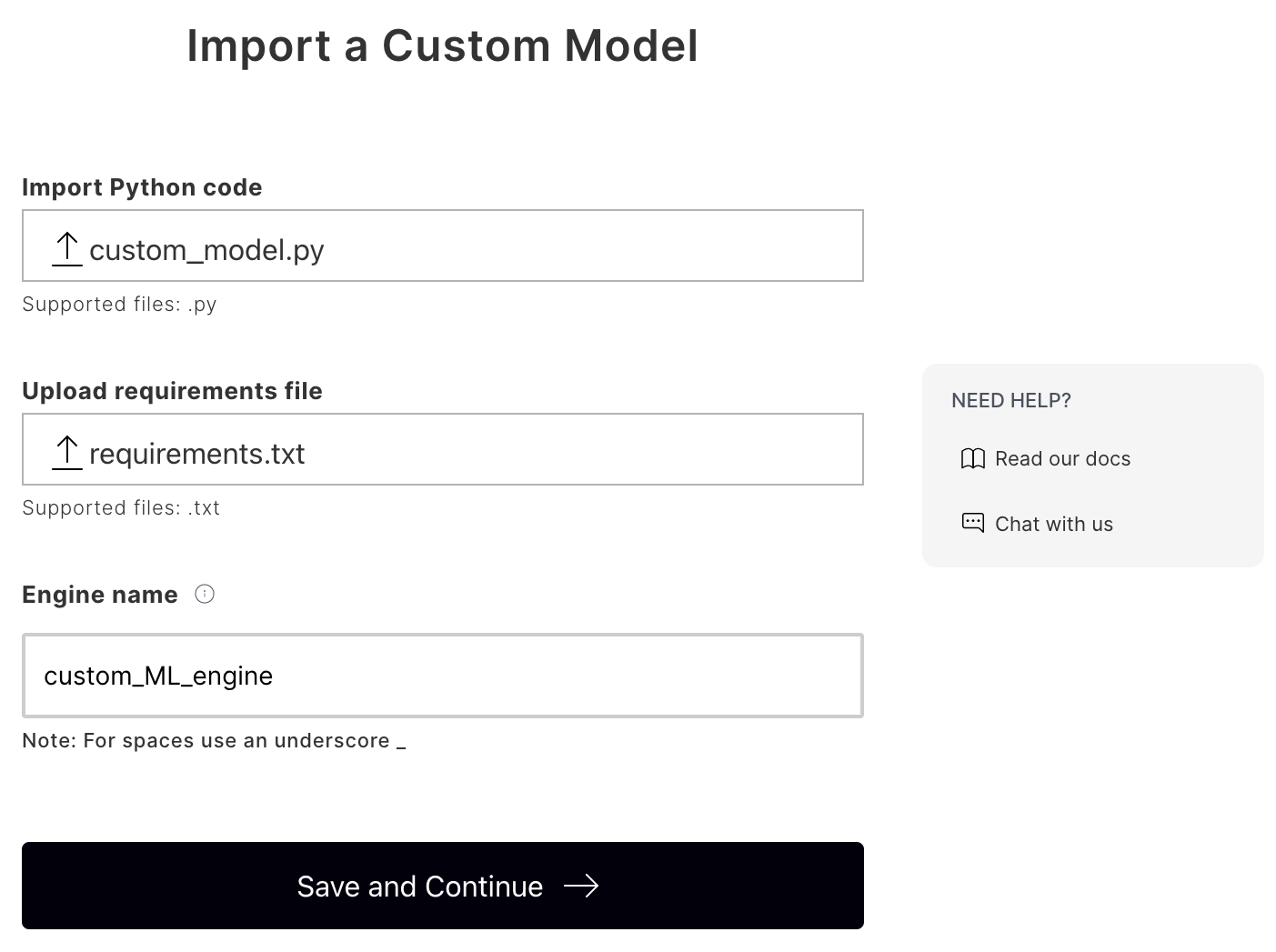
Here we upload the custom_model.py file that stores an implementation of the model and the requirements.txt file that stores all the dependencies.
Once the model is uploaded, it becomes an ML engine within MindsDB. Now we use this custom_ML_engine to create a model as follows:
CREATE MODEL custom_model
FROM my_integration
(SELECT * FROM my_table)
PREDICT target
USING
ENGINE = 'custom_ML_engine';
SELECT input.feature_column, model_target_column
FROM my_integration.my_table as input
JOIN custom_model as model;